第 3 期:数字化新体验 | HexaDB 在 AP 场景下的差异化能力
在数仓和大数据系统中,数据规模越来越大的同时,数据分析的维度也越来越多,创新型业务对数据计算的实时性要求也越来越高,这个领域也逐渐成为关注的焦点。多年来,市场上涌现了众多产品能力平台,这些产品的能力项逐渐趋同,主要提供数据集成、数据规范、数据开发、数据质检、数据安全和数据开放等常规功能。然而,差异化的能力点越来越少,导致产品之间的竞争愈发激烈,甚至有些产品一味地拓展功能清单的长度,具体场景化解决客户痛点的能力不足。
在数据开发治理的过程中,小六发现一些高频痛点问题很大程度上影响了产品的使用效率和成本,例如在数据来源没有明显更新的情况下,周期性调度作业无效执行,浪费系统资源;编写了一个 SQL 加工脚本,由于执行成本较高导致磁盘负载过高;不懂 SQL 语句编写的业务分析人员无法高效的查询使用数据;加工出来的数据需要依赖第三方 BI 软件才能生成报表;无法高效拿到多个 API 上下文加工后的数据;而 HexaDB 从产品能力上有效地解决了这些问题。
HexaDB 是一套具备 HTAP 能力的产品包,包括 HTAP 型数据库海纳、数据开发管理软件鲁班、数据库迁移工具灵渠,为客户提供数据库与数据仓库一体化、一站式解决方案。HexaDB 产品包的各产品也可以独立使用,比如海纳也可以单独用作交易型数据库、数据仓库、甚至数据中台的存算引擎;鲁班可以用作数仓系统中的数据开发治理软件。小六本次选取了几个典型客户痛点,为大家简要介绍 HexaDB 在分析型计算的场景里给用户带来的新的体验。
场景一:基于事件触发的数据开发作业调度能力。
通常在对数据进行加工治理时,选择加工作业的生效日期和调度周期后,作业会按照调度周期在生效日期内按时循环加工。某热力公司在项目实施过程中采用这种方式遇到了问题,该项目的供热工单业务系统的数据更新不是连续的,且数据变更的时间不确定。尽管数据量变化较小,但却对数据的实时性有很高的要求,需要对变化的数据进行实时加工处理并提供给上层的应用使用,因此将加工作业的调度周期设置为 1 分钟,这就造成在一个甚至多个调度周期内,由于原始数据表的数据量都不会发生变化,或数据量变化较小,多次调度无意义且消耗系统资源。
针对这个问题,HexaDB 利用自研的分布式关系型数据库引擎,使加工作业在每次调度执行前通过引擎提供的系统统计表获取原始数据表在周期内的数据变化情况,结合作业数据量变化的阈值设置可以决定本次作业是否执行或跳过,这就能最大程度的避免无效调度,既能节省系统资源,又能保证数据治理的时效性。
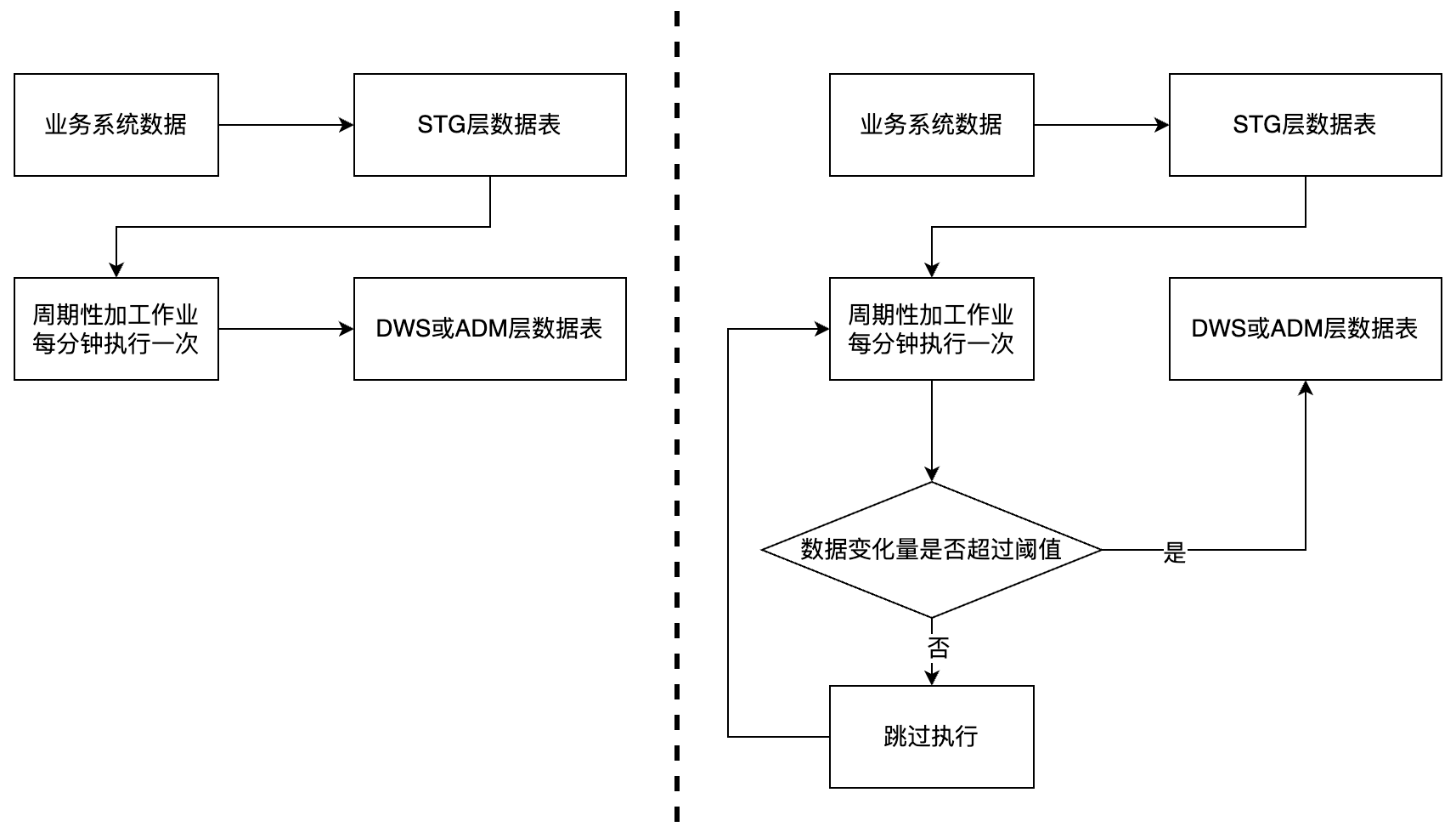 图 1-事件触发机制前后流程对比
图 1-事件触发机制前后流程对比场景二:SQL 成本预估能力。
在客户数仓建设的过程中,通常首先需要把各个业务系统的数据汇总到数仓的 STG 层数据表,然后结合客户的数据模型、数据标准和业务分析需求,数据开发治理工程师从 STG 层数据表加工成 ODS 层数据表、DWD 层数据表、DWS 层数据表,这就需要编写大量复杂的 SQL 脚本,例如 INSERT INTO 目标表名 (列 1, 列 2, 列 3, ...) SELECT 列 1, 列 2, 列 3, ... FROM 源表名 1,源表名 2,源表名 3,... WHERE 连接查询条件;如果 SQL 语句涉及的数据表的数据量较大、复杂的连接查询或者大量的聚合函数,传统的基于 Hive 和 Hadoop 技术体系的数仓并不能有效的预估 SQL 的执行成本和执行时长,因此无法科学地编排作业任务,这就有可能造成加工作业上线运行后,作业中某些节点消耗大量的系统资源并迟迟不能运行完成。
某云服务厂商在项目实施过程中遇到了此类问题,加工作业里面涉及了几张大数据量表的查询和更新,引发系统内存、CPU 和磁盘资源的瓶颈,造成整个数仓平台运行不稳定。针对这个问题,HexaDB 利用自研的分布式关系型数据库引擎,利用平台资源空闲时段对加工作业涉及的每个层的数据表执行 ANALYZE 命令用于收集和更新统计信息,帮助优化查询计划。当数据开发治理工程师编写 SQL 脚本的过程中,引擎会根据执行计划返回预估的执行成本、执行时间和行数估算,进而提醒工程师谨慎上线这个加工作业或者进一步优化 SQL 语句的编写逻辑。
场景三:Text-to-SQL 智能消费能力。
很多客户建设数仓都是为了更好的分析和使用数据,实现业务数据化和数据业务化,挖掘数据的潜在价值。传统数仓使用数据都是通过数据开放的功能,首先把数据表发布成资产,然后根据业务需求申请对应的数据字段权限,很大可能这些数据字段分布在不同的数据表中,这就造成用户需要申请多张数据表的权限问题,权限审批通过后,用户通过调用数仓平台提供的数据消费 API 执行编写的业务查询 SQL 获取数据,这就要求用户具备一定的技术底子,会编写复杂查询 SQL 才能高效使用数据。
某省会城市核心区数据中台项目实施过程中遇到了类似的问题,治理的粒度比较细,数据字段比较分散,使用数据的上层应用的开发人员由于短时间内需要编写大量的数据查询 SQL,这就造成编写出来的 SQL 性能较差、逻辑不清晰、可读性差。
针对上面存在的问题,HexaDB 结合 AIGC 技术,实现了智能消费能力,首先利用业务需要的多个数据字段在整个仓内检索,根据检索结果选取数据字段所在的多张数据表,把这些数据表的 DDL 信息同步给 AI,然后用户输入自然语言详细描述自己的使用数据需求,使用 AI 生成对应的业务查询 SQL 并生成数据视图,这样用户只需要申请这个数据视图的访问权限,避免直接申请多张数据表的权限,另外不太熟悉 SQL 语句编写的业务人员也可以使用数据,降低了数据使用门槛,提高了数据使用效率。
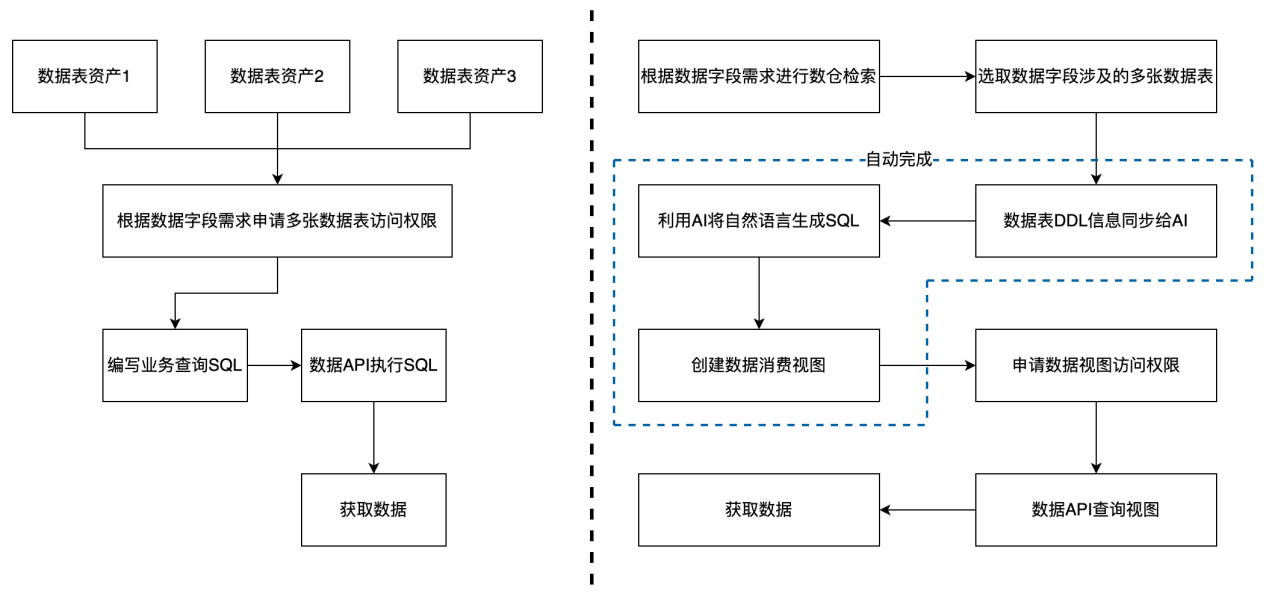 图 2-智能消费流程前后对比
图 2-智能消费流程前后对比场景四:业务卡片与报表组装能力。
随着业务的发展,每个客户的数据量越来越大、数据种类越来越多,如何从这些数据中挖掘潜在的价值,报表的需求应运而生,基本上每个客户都有报表的需求。
某云服务厂商使用 Hive 和 Hadoop 套件建立了经典的数仓系统,首先通过开源 ETL 组件以及 RPA 实现数据从 OLTP 系统到数仓系统的动态复制,然后在数仓系统里面完成数据的加工,最后再利用第三方的 BI 报表软件或者把加工好的数据下载到 Excel,才能完成报表的开发,这个过程数据处理的链路较长、数据的质量和时效性差。
以前主要用于以 T+1 的实效性每天生成报表,供业务主管决策之用,还可以满足需求,但是随着数字化转型的深入,企业要求数仓系统能为一线销售和售后服务团队提供实时辅助决策,快速生成可靠性较高的业务报表,现在的技术架构已经无法满足业务需求。
针对这个问题,HexaDB 提供了轻量化、一体化的业务报表生成能力,首先对数仓内加工好的数据可以让用户编写 SQL 语句完成交互式查询,并对查询结果进行可视化拖拽配置,生成一张张具有业务含义的卡片,例如 2023 年订单数量与订单金额统计、2023 年各月份销售情况汇总、2023 年各区域销售情况统计等,然后可以进一步创建业务报表面板,根据业务分析需求动态选择对应的业务卡片加入到面板,快速生成一份时效性和可靠性较高的业务报表,整个报表制作过程都在数仓平台完成,无需再和第三方 BI 报表软件进行数据对接,无需再把数据下载到 Excel 制作报表,缩短了数据处理的链路,保障了数据的时效性和质量。
另外,随着业务卡片的积累,可以形成业务卡片集市,根据不同数据用户的个性化分析需求,制作千人千面的业务报表。
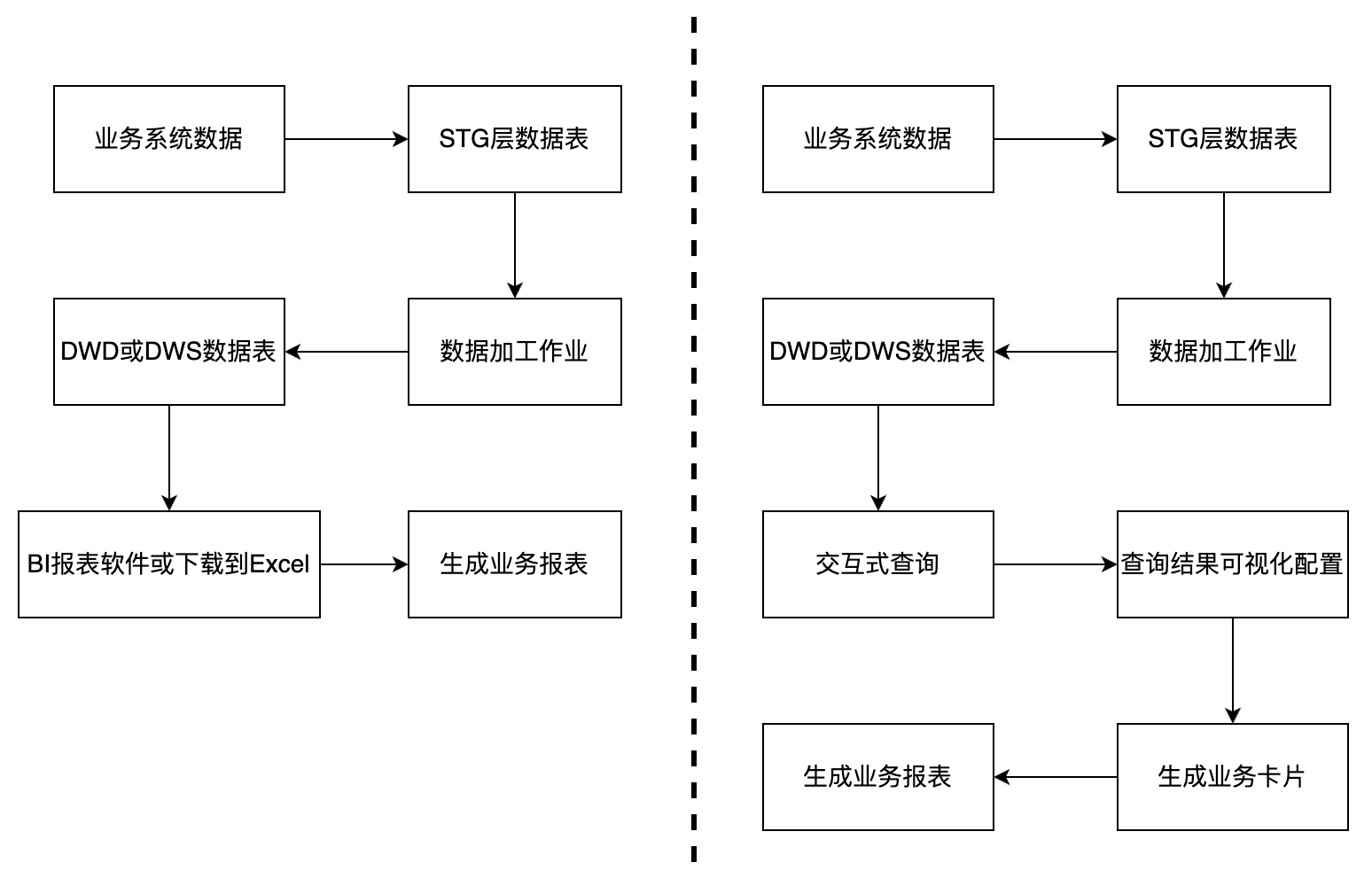 图 3-数据报表生成流程前后对比
图 3-数据报表生成流程前后对比场景五:JMeter 脚本集成能力。
在数仓建设的过程中,我们需要把各种业务系统的数据集成到数仓,很多业务系统由于权限安全管控并不能提供数据库的直接访问,只能通过业务系统提供的 API 获取数据,用户需要先使用自己的密钥(AKSK)获取具有时效性的数据访问令牌(token),之后可以使用该令牌(token)多次访问数据 API 接口,获取数据。
某省会城市大数据系统需要汇集区域内所有的特种车辆数据,供上层的挂图作战应用使用,例如展示特种车辆的信息、特种车辆实时的位置和轨迹信息等,为了获取这些数据,大数据系统需要对接特种车辆管理系统,特种车辆管理系统只能提供多个查询数据的 API,并且这些 API 之间需要上下文的数据传递,例如先获取区域车辆的列表信息,再根据具体车辆的 ID 获取车辆的实时信息,大部分的数仓系统仅提供了单个 API 的数据集成能力,并没有实现 API 的流程编排和上下文数据传递,这就无法有效的集成这种类型的数据。
针对这个问题,HexaDB 提供了基于 JMeter 脚本的 API 数据集成能力,JMeter 已经具备非常成熟的 API 流程编排和上下文数据传递能力,用户首先在 JMeter 里面编写复杂的 API 处理脚本并把处理好的数据通过调用 HexaDB 提供的数据写入 API 插入到 HexaDB 数据表,然后通过周期性运行数据集成作业调用 JMeter 执行引擎完成 API 数据的集成。采用这个解决方案,可以满足大部分的 API 数据接入场景,提高了 API 数据的接入效率。
未来,HexaDB 在大数据开发治理领域将结合自研的 HTAP 库仓一体引擎继续探索并引入新的技术和方法,构建差异化产品能力,以满足用户不断变化的需求,真正解决客户的高频痛点问题,并实现产品的持续升级和优化。

