第 21 期:HexaDB分布式数据库中的数据重分布与Stream算子
数据重分布
一般来说,分布式数据库在以下两种场景时,需要执行数据重分布:
(1)在分布式数据库中执行 JOIN 操作时,当参与 JOIN 的表在集群中的数据分布方式无法在各节点本地直接满足 JOIN 条件时,就需要通过数据重分布来确保相同关联键的数据能汇聚到同一节点进行计算。
(2)在分布式数据库中执行 AGG 操作时,当任意分组的数据行,根据在集群中的数据分布方式无法保证在单一节点时,也需要数据重分布来确保落入该分组的数据能汇聚到同一节点进行计算。
具体对应到 HexaDB 分布式数据库,有如下典型场景涉及数据重分布:(1)当参与 JOIN 的表,其 JOIN 条件如果不是包括分布列上等值条件,则可能需要数据重分布;(2)执行 AGG 操作时,如果分组列不包括所在表(包括中间结果)的分布列,则需要数据重分布。
在分布式数据库中,AGG 操作与集中式 AGG 相比,执行流程上相当于在分组计算之前增加一操作:单表在分组列上执行自连接后去重。而分组计算本身差异则不大,因此下文除非必要,仅述及 JOIN 操作,而忽略 AGG 操作。
JOIN 条件或 JOIN 类型导致数据重分布需求
HexaDB 分布式数据库通常会将表按某个字段(或多个字段组合)作为分布键,将数据 Hash 到不同节点,以实现数据分片和并行处理。
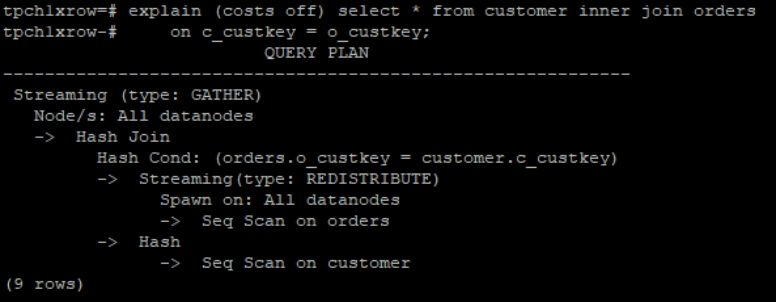
比如,如下 TPCH 标准测试涉及的表 CUSTOMER,ORDERS。
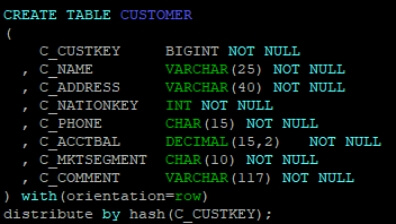 CUSTOMER
CUSTOMER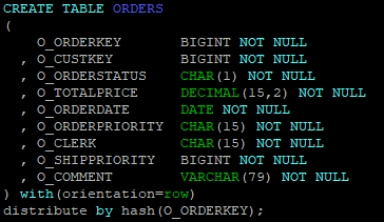 ORDERS
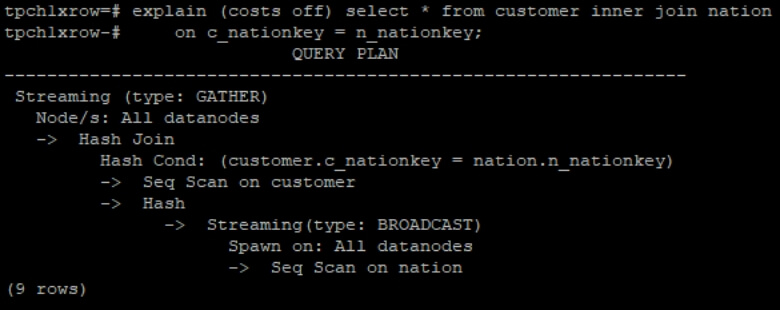
ORDERS其中 CUSTOMER 表按 C_CUSTKEY 分布,ORDERS 表按 O_ORDERKEY 分布。当执行“JOIN ON C_CUSTKEY = O_CUSTKEY”时,由于两表分布键不同,数据在节点间的分布无关联性,进而无法直接在同一节点完成 JOIN。
如何解决?需将其中一张表按 JOIN 条件字段(如 O_CUSTKEY)重新哈希分布,使相同(C_CUSTKEY/O_CUSTKEY)的数据汇聚到同一节点。更一般的情形是,当两表分布键与 JOIN 条件无关时,必须将两表都按 JOIN 条件字段执行数据重分布。
上述情形中 JOIN 类型为 INNER JOIN。进一步考虑扩展情形, 如果 JOIN 类型为 OUTER JOIN(包括 LEFT OUTER JOIN,RIGHT OUTER JOIN, FULL OUTER JOIN),则需要将内表通过广播(数据重分布的特殊衍生情形)完成数据对齐。
表的分布方式导致数据重分布需求
除按分布键 Hash 值分布外,HexaDB 分布式数据库还支持 RANGE/LIST 分布,以及 ROUNDROBIN 分布。RANGE/LIST 分布对 JOIN 的影响,与 Hash 分布的影响类似。这里不赘述。
ROUNDROBIN 分步轮流将数据分散到各节点,也就是说,无论 JOIN 条件是什么,其他节点都可能存在满足此 JOIN 条件的数据。于是,当 ROUNDROBIN 分布表与其他表 JOIN 时,无论 JOIN 条件是什么,都需重分布以确保关联键数据对齐。
Stream 算子
与开源社区命名传统保持一致,我们以 Stream 命名执行数据重分布的算子。HexaDB 分布式数据库支持如下类型 Stream 算子:
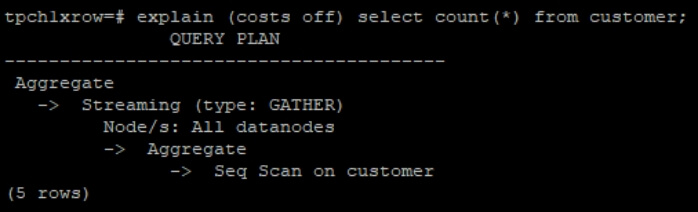
(1)Gather 类型
Gather Stream 算子将多个节点的数据收集到一个目标节点。常见的适用场景:最终聚合结果的汇总(如 COUNT、SUM);或者将并行处理的结果返回给客户端。
(2)Broadcast 类型
Broadcast Stream 算子将一个表的全部数据复制到所有目标节点。常见适用场景:小表与大表 JOIN 时,广播小表到所有处理大表的节点。
(3)Redistribute 类型
Redistribute Stream 基于哈希算法重新分布数据,确保相同键值的数据被发送到同一目标节点。常见适用场景:JOIN 操作中,将两个表的关联键按相同哈希函数分布到同一节点;以及聚合操作中,将相同分组键的数据发送到同一节点。
数据重分布使用最佳实践
Rule 0 -- 避免数据重分布
数据重分布不是免费的;Stream 算子不可避免的带来如下开销:
- 网络开销:网络处理延时显著大于内存访问延时,甚至大于高性能磁盘访问延时。另外,大量数据跨节点传输会挤占网络带宽,尤其在集群规模大或数据量多时。
- 计算开销:重分布需进行哈希计算和数据分片,增加 CPU 和内存消耗。
所以,如有可能,我们应当避免数据重分布。
避免数据重分布需遵循如下最佳实践:
- 数据库物理设计时合理设计表分布键
将高频 JOIN 条件字段设为表的分布键,例如 ORDERS 和 CUSTOMER 按 CUSTOMER KEY 分布,避免 JOIN 时对左右表都执行数据重分布。如果两表分布键相同且 JOIN 条件为分布键,则直接在各节点本地 JOIN,无需重分布。
- 利用复制表优化大小表 JOIN
复制表在每个数据处理节点上保存一份完整的数据。将小表(比如维度表)定义为复制表,与大表 JOIN 时无需执行数据重分布。
减少重分布数据量
如果数据重分布无法避免,退而求其次我们应尽可能减少重分布数据量。
数据量较大的表,可以使用 Hash 分布方式。Hash 分布表在定义分布键时,除前述考虑高频 JOIN 条件字段外,需要综合考虑高频过滤条件字段、分布均匀且 UNIQUE 值较多的字段。
另外,一些通用的 SQL 查询最佳实践可以排上用场,比如仅查询必需列(即少用*),增加合理过滤条件等,以减少通过网络传输的数据量。
优化数据重分布,提升分布式查询性能
在分布式数据库中,数据重分布是保证 JOIN 和 AGG 操作正确性的关键机制,但同时也可能成为性能瓶颈。未来,HexaDB 将持续优化数据分布策略和 Stream 算子的执行效率,帮助用户在高并发、大数据量场景下实现更极致的查询性能。

