第 7 期:HexaDB慢查询诊断“三件套”:揪出隐藏的病灶
1、背景
某知名车厂因为业务发展需要,采用 HexaDB-T 集群替换原有开源数据库,日增数据近百亿,服务于国内千万级用户。在前期上线试运行期间,发现某个更新数据接口时延超出预期。在问题解决的过程中,慢查询诊断“三件套”( Statement、Statement History、DFC)发挥着至关重要的作用,小六今天在这篇文章中向大家分享“三件套”应用过程的心得。
2、问题描述
客户某个更新接口平均时延达到了 300ms,接口调用频率为每秒 5000 次左右,根据 application name 定位到和这个接口相关的表和语句信息。
表定义如下:主键为 ID 和 CDR_PERIOD,使用独立表空间
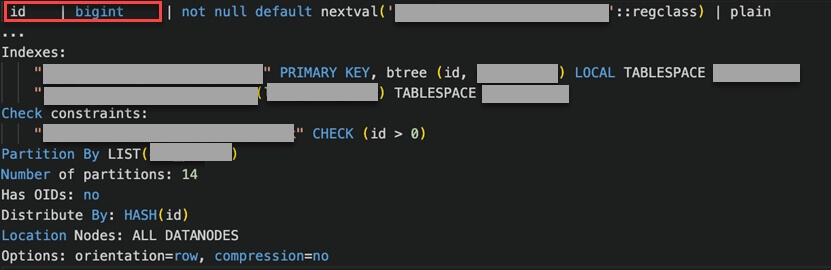
update 语句如下:可见这是一个单表使用主键的更新操作。

好的,相信您不到两分钟,就对这个问题的现象已经了如指掌。
3、解决过程
此时,小六来复盘一下解决此类问题的基本思路:

STEP1:排除系统资源瓶颈
这一步的目的是看硬件资源和数据库资源是否存在瓶颈,拖慢 SQL 的执行。不同的请求对资源的需求不一样,上述基于主键的 update 可能会在磁盘 IO、锁资源上有较多需求。
检查的结果是,发现硬件资源并无瓶颈,整个系统大概占用 50%的 CPU 和 30%的 IO,从这个目前还看不出明显的瓶颈,但我们要记住 50%和 30%这两个值,后面我们还会继续关注它们。
在数据库资源的使用上,看不出内存有明显的瓶颈(MEMORY_NODE_DETAIL、SHARED_MEMORY_DETAIL、SESSION_MEMORY_DETAIL),线程池(global_threadpool_status)空闲较多,并无限流发生,系统 TOP 10 的 EVENT(wait_events)也是正常的,同时并无长时间的锁等待。至此,我们看起来一无所获,所幸的是,我们并没有在这一步上花费太多的时间。
STEP2:分析历史执行情况
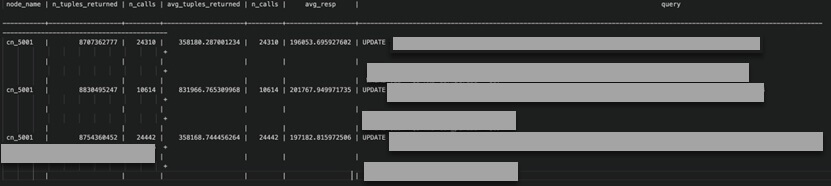
主要判断:是长期还是突发的性能劣化,根据归一化 SQL 性能统计(global_statement)历史,我们可以看出,这个问题是从业务一开始就有的。内核处理时间(avg_resp 列)稳定在 200ms 左右。此时第一个非常重要的疑点出现了,请注意 avg_tuples_returned 的值,居然高达几十万,这意味着每条查询都扫描了几十万行的数据,这对于一个基于主键过滤的 SQL 来说是不正常的,极有可能意味着索引失效了。
在 1:1 的测试环境针对这条 SQL 执行 explain,获取执行计划,发现 SQL 的执行时间只有 5ms,执行计划完全符合预期。

既然没有锁冲突,基于 avg_tuples_returned 的高水位,我们要确认下这张表的历史索引扫描情况:

果不其然,idx_scan 很低,seq_scan 很高。我们又确认了主键索引的状态,是启用并且健康的。那就去看为什么索引不生效吧。
STEP3:慢查询日志,按图索骥
HexaDB 的慢查询日志将记录达到慢查询阈值的详细执行过程,包括内核各阶段的时间消耗、IO 消耗、网络消耗、锁申请与释放情况、本次的查询计划、查询参数等,详情见《HexaDB 开发者指南》。不过客户设置的慢查询阈值是 3s,这个 update 语句没有达到慢 SQL 的标准。我们不能在现网将慢 SQL 的阈值调整为 200ms 这么低的值,这样将会对现网的业务造成一定的冲击。
STEP4:定点跟踪 SQL 执行
所幸的是,我们可以定点定时开启对这个 update 语句的单点 SQL 的执行跟踪,得到所有 STEP3 所述的指标。

上面语句中的 4202763078 即为该条 SQL 的归一化 SQLID,L2 为跟踪级别。
通过开启定点跟踪 10s,我们从 statement_history 中获取了该 update 的单次详细执行情况,以下为截取的两个片段:
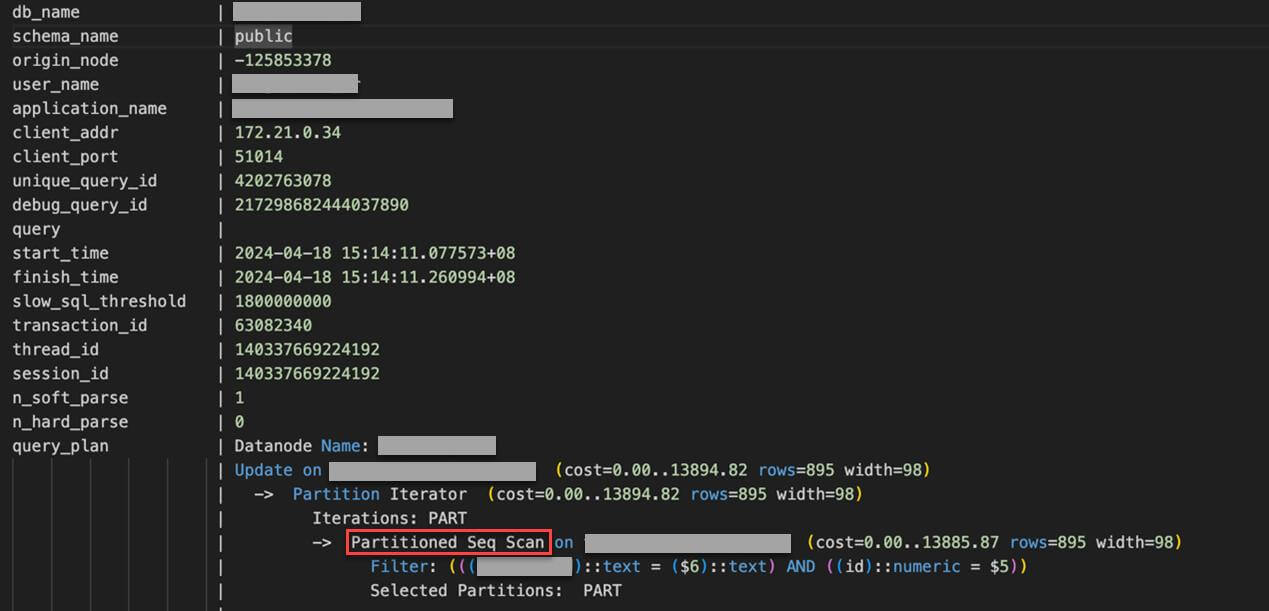
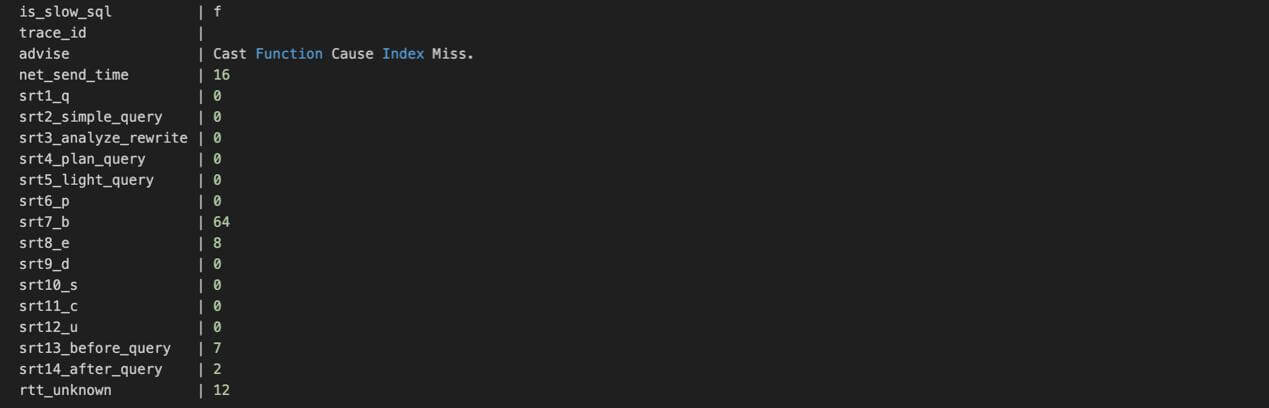
上面这些指标明确表征,由于 ID 这个字段发生了类型转换,导致了实际的执行计划是 Seq Scan。这与 STEP2 中我们自行获取的执行计划大相径庭。因为我们在命令行模拟的 SQL,ID 的数据类型是 bigint,符合表定义,不会发生类型转换,而客户使用 JDBC 执行的 SQL,将 ID 的类型定义为 numeric,执行时发生了强制类型转换,导致无法使用主键索引。
接下来,解决方案就很明显了,其一是将 JDBC 客户端指定的数据类型转换为 bigint,其二是将数据库类型在线变更为 numeric。最终客户选择了后者。
变更后,我们进行了一段时间的监控,UPDATE 语句达到了 3ms 的平稳响应。再将上面所做的步骤重新检验了一遍,全部符合预期。对于 STEP1 中系统 CPU 和 IO 使用率,实施完变更后,CPU 降低至 30%,IO 使用率降低至 20%,这也符合解决方案的预期。
4、后记
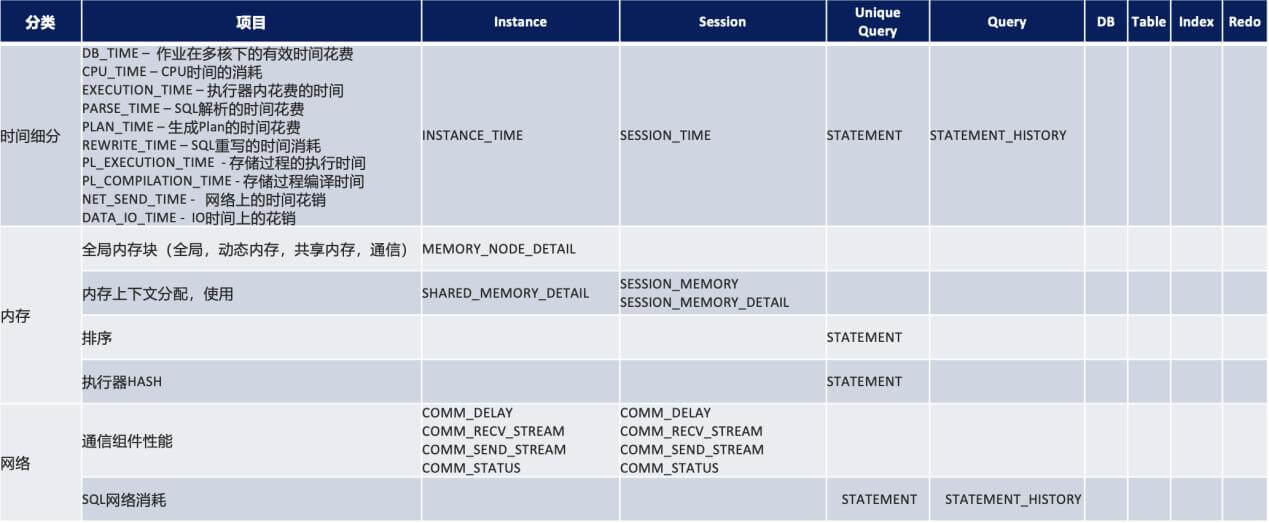
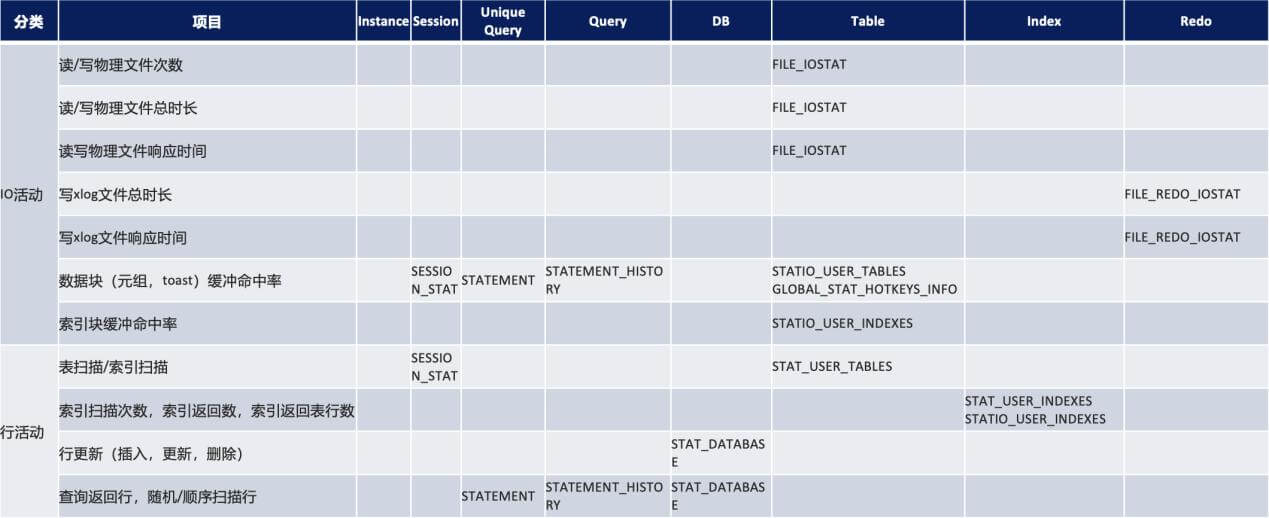
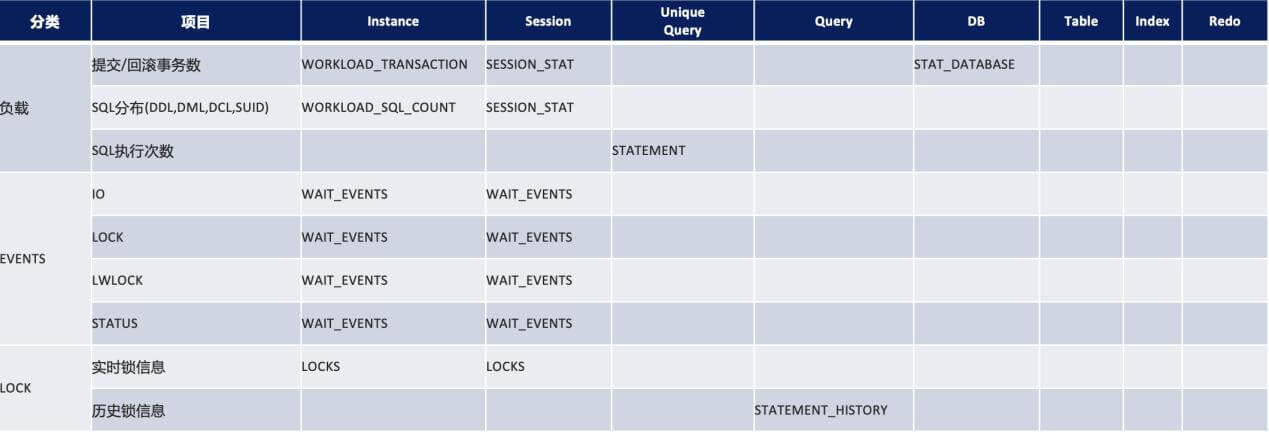
这个案例中,介绍了慢 SQL 诊断的一般流程:由外而内(系统级到语句级),自下而上(计算资源到 SQL 执行),使用了“statement”、“statement history”、“DFC(动态定点追踪)” 三件套来辅助我们。HexaDB 海纳提供了一系列的数据库性能诊断手段,下表从 Instance、Session、Unique Query、Query、DB、Table、Index、Redo 八个维度分门别类,帮助用户更快熟悉 HexaDB 的日常运维诊断。